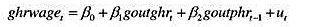题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
考虑一个简单模型,来估计一所大型公立大学中,毕业生拥有计算机对其大学平均成绩的影响(其中PC
考虑一个简单模型,来估计一所大型公立大学中,毕业生拥有计算机对其大学平均成绩的影响(其中PC
是一个表示拥有个人计算机的二值变量):
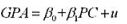
(i)为什么PC可能与u相关?
(ii)解释为什么PC可能与父母的年收入相关。这是否意味着父母的收入作为PC的IV还不错?为什么?
(iii)假设四年前学校为大约一半的学生提供了购买计算机的资助,而获得资助的学生是随机挑选的。仔细解释你如何利用这一信息为PC构造一个工具变量。
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“考虑一个简单模型,来估计一所大型公立大学中,毕业生拥有计算机…”相关的问题
更多“考虑一个简单模型,来估计一所大型公立大学中,毕业生拥有计算机…”相关的问题