 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
考虑一个雇员水平的模型(iv)讨论第(iii)部分对于利用企业层次的平均数据进行WLS估计的意义,其
考虑一个雇员水平的模型(iv)讨论第(iii)部分对于利用企业层次的平均数据进行WLS估计的意义,其
考虑一个雇员水平的模型

(iv)讨论第(iii)部分对于利用企业层次的平均数据进行WLS估计的意义,其中第i次观测所用的权数就是通常的企业规模。
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
考虑一个雇员水平的模型
(iv)讨论第(iii)部分对于利用企业层次的平均数据进行WLS估计的意义,其中第i次观测所用的权数就是通常的企业规模。
如果结果不匹配,请 联系老师 获取答案
 更多“考虑一个雇员水平的模型(iv)讨论第(iii)部分对于利用企…”相关的问题
更多“考虑一个雇员水平的模型(iv)讨论第(iii)部分对于利用企…”相关的问题
考虑一个雇员水平的模型
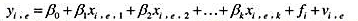
其中无法观测变量f是在一个给定的企业i内,对每个雇员的“企业效应”。误差项vi,e是企业i中雇员e所独具的。诸如方程(8.28)中的综合误差就是ui,e=fi+ui,e.

(iv)讨论第(ii)部分对于利用企业层次的平均数据进行WLS估计的意义,其中第i次观测所用的权数就是通常的企业规模。
本题利用WAGEPAN.RAW中的数据。
(i)考虑非观测效应模型

(iv)现在,容许是否加入工会的差别(与受教育水平一起)在不同时期有所变化,用FD估计这个方程。1980年加入工会与不加入工会的估计工资差别是多少?1987年呢?这个差别在统计上显著吗?
(v)检验工会关系差别在不同时期没有发生变化的虚拟假设,并根据你对第(iv)部分的回答讨论你的结论。
(i)考虑静态非观测效应模型

其中,enrolit表示学区总注册学生人数,lunchit表示学区中学生有资格享受学校午餐计划的百分数。(因此lunchit是学区贫穷率的一个相当好的度量指标。)证明:若平均每个学生的真实支出提高10%,则math4it约改变β1/10个百分点。
(ii)利用一阶差分估计第(i)部分中的模型。最简单的方法就是在一阶差分方程中包含一个截距项和1994~1998年度虚拟变量。解释支出变量的系数。
(iii)现在,在模型中添加支出变量的一阶滞后,并用一阶差分重新估计。注意你又失去了一年的数据,所以你只能用始于1994年的变化。讨论即期和滞后支出变量的系数和显著性。
(iv)求第(iii)部分中一阶差分回归的异方差-稳健标准误。支出变量的这些标准误与第(iii)部分相比如何?
(v)现在,求对异方差性和序列相关都保持稳健的标准误。这对滞后支出变量的显著性有何影响?
(vi)通过进行一个AR(1)序列相关检验,验证差分误差rit=Δuit含有负序列相关。
(vii)基于充分稳健的联合检验,模型中有必要包含学生注册人数和午餐项目变量吗?
本题使用KIELMC.RAM中的数据。
(i)变量dist是从每个房屋到焚烧炉位置的英尺距离。考虑模型

(ii)估计第(i)部分中的模型并按通常的方式报告结果。解释y 81-log(dit)的系数。你得到什么结论?
(iii)在方程中增加age, age2, rooms, baths, log(int st), log(land) 和log(area)。现在, 你对焚烧?对房屋价值的影响会作出什么结论?
(iv)为什么在第(ii)部分log(dist)的系数为正并且统计显著, 而在第(ii)部分却不是这样?这说明了第(iii)部分中控制变量的什么?

其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型,并报告通常的标准误。为使得ai的期望值可以非零,你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差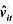 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用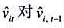 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?
(vi)定义支出的总(或长期)效应为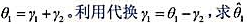 的标准误。
的标准误。
(i)用虚拟变量demwins来代替教材(10.23)中的demvote,并用通常的格式报告结果。哪些因素影响获胜概率?请用截至1992年的数据。
(ii)有多少个拟合值小于0?有多少个拟合值大于1?
(iii)采用下面的预测规则:如果demwins>0.5,你就可以预测民主党会获胜;否则,共和党将获胜。那么,在这20次选举中,这个模型有多少次正确地预测了实际结果?
(iv)代入1996年的解释变量值。预测克林顿赢得这次选举的可能性有多大。事实上,克林顿获胜了,你的预测结果是否与事实相符?
(v)对误差中的AR(1)序列相关,做异方差-稳健:检验。你有何发现?
(vi)求出第(i)部分中估计值的异方差-稳健标准误。!统计量有什么明显的变化吗?
利用数据集401KSUBS.RAW。
(i)利用OLS估计e401k的一个线性概率模型,解释变量为inc,inc²,age,age²和male。求通常的OLS标准误和异方差-稳健的标准误。它们有重要差别吗?
(iii)对第(i)部分估计的模型求怀特检验,并分析系数估计值是否大致对应于第(ii)部分中描述的理论值。
(iv)在验证了第(i)部分的拟合值都介于0和1之间后,求这个线性概率模型的加权最小二乘估计值。它们与OLS估计值有重大差别吗?
利用PHILLIPS.RAW中的数据。
(i)估计失业率的AR(1)模型。用这个方程预测2004年的失业率。将它与2004年的实际失业率进行比较。(你可以从近年的《总统经济报告》中找到这个数据。)
(ii)在第(i)部分的方程中增加通货膨胀的一期滞后。inft-1统计上显著吗?
(iii)利用第(ii)部分中的方程预测2004年的失业率。这个结果比第(i)部分的结果更好还是更糟?
(iv)利用教材6.4节中的方法构造2004年失业率的一个95%的置信区间。2004年的实际失业率位于这个区间内吗?
文件CEOSAL2.RAW包含了177位首席执行官的数据,并可用来考察企业业绩对CEO薪水的影响。
(i)估计一个将年薪与企业销售量和市场价值相联系的模型。让这个模型对每个自变量的变化都具有常弹性。以方程的形式写出结论。
(ii)在第(i)部分的模型中增加profits。为什么这个变量不能以对数形式进入模型?你会说这些企业业绩变量解释了CEO薪水波动中的大部分吗?
(iii)在第(ii)部分的模型中增加ceoten。保持其他条件不变,延长一年CEO任期,估计的百分比回报是什么?
(iv)求出变量log(mktval)和prots之间的样本相关系数。这些变量高度相关吗?这对OLS估计量有什么影响?
人口特征方面的数据。目的是想考察快餐店是否在黑人更集中的区域收取更高的价格。
(i)求出样本中prpblck和income的平均值及其标准差。prpblck和income的度量单位是什么?
(ii)考虑一个模型,用人口中黑人比例和收入中位数来解释苏打饮料的价格psoda:
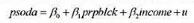
用OLS估计这个模型并以方程的形式报告结果, 包括样本容量和R。(报告估计值时不要使用科学计数法。)解释prpblck的系数。你认为它在经济上算大吗?
(iii) 将第(ii)部分得到的估计值与psoda对prpblck进行简单回归得到的估计值进行比较。控制收入变量后,这种歧视效应是更大还是更小了?
(iv)收入价格弹性为常数的模型可能更加适合。报告如下模型的估计值:

(vi)求出1og(income)和prppov的相关系数。大致符合你的预期吗?
(vii)评价如下说法:“由于log(income)和prppov如此高度相关,所以它们不该进入同一个回归。”

















