

 如果结果不匹配,请
如果结果不匹配,请 
 更多“随机森林是哪种类型的学习算法()?”相关的问题
更多“随机森林是哪种类型的学习算法()?”相关的问题
第1题
随机森林利用随机的方式将许多决策树组合成一个森林,每个决策树在分类的时候决定测试样本的最终类别。它的优点是()。
A.级别划分较多的属性不会影响模型效果
B.在某些噪音较大的分类或回归问题上不会过拟合
C.每次学习使用不同训练集,一定程度避免过拟合
D.能够处理高纬度的数据,并且不做特征选择
第2题
组合分类器主要有哪几种类型()
A.Bagging、Boosting、Stacking
B.Bagging、Ababoost、Stacking
C.Bagging、Ababoost、随机森林
D.Ababoost、随机森林、Stacking
第6题
下面关于机器学习的说法中,正确的有()。
A.监督学习的监督体现在所有机器要处理的数据实现都要由人为定义好相应的类别,再对分类算法进行训练,最后得到可以使用的分类器
B.按照不同的学习理论划分,机器学习模型可以分为有监督学习、半监督学习、无监督学习以及强化学习等不同类型
C.有监督学习的数据集有标签,无监督相比于有监督,没有训练过程,而是直接拿数据进行建模分析
D.在实际应用中,机器学习主要以无监督学习或半监督学习方式为主
第8题
全局梯度下降算法、随机梯度下降算法和批量梯度下降算法均属于梯度下降算法,以下关于其有优缺点说法错误的是()
A.全局梯度算法可以找到损失函数的最小值
B.随机梯度算法可以找到损失函数的最小值
C.全局梯度算法收敛过程比较耗时
D.批量梯度算法可以解决局部最小值问题
第10题
试扩充深度优先搜索算法,在遍历图的过程中建立生成森林的子女-兄弟链表。算法的首部为其中,指
试扩充深度优先搜索算法,在遍历图的过程中建立生成森林的子女-兄弟链表。算法的首部为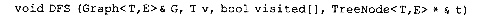 其中,指针t指向生成森林上具有图顶点v信息的根结点。(提示:在继续按深度方向从根v的某一未访问过的邻接顶点w向下遍历之前,建立子女结点。但需要判断是作为根的第一个子女还是作为其子女的右兄弟链入生成树)
其中,指针t指向生成森林上具有图顶点v信息的根结点。(提示:在继续按深度方向从根v的某一未访问过的邻接顶点w向下遍历之前,建立子女结点。但需要判断是作为根的第一个子女还是作为其子女的右兄弟链入生成树)
第11题
小张学习了财务自由课程,下面关于资产与负债的说法,正确的有()。
A.投资者应该尽可能的把钱变成资产,哪种类型都可以
B.识别生钱资产、耗钱资产、其他资产的能力是财商的一部分
C.获得优质生钱资产的能力是财商的一部分
D.负债一般会有到期期限,个人常见的负债有:房贷、车贷、消费贷、信用卡欠款等
















