

 如果结果不匹配,请
如果结果不匹配,请 
 更多“在回归分析中,样本量的个数要多于解释变量的个数()”相关的问题
更多“在回归分析中,样本量的个数要多于解释变量的个数()”相关的问题
本题使用HTV.RAW中的数据。
(i)基于整个样木, 利用解释变量educ、abil、exper、nc、west、south和urban, 利用OLS估计log(wage)的一个模型。报告教育的估计回报及其标准误。
(ii)现在, 仅利用educ<16的人群来估计第(i) 部分中的方程。样本损失了多大的比例?现在, 多读一年书的估计回报是多少?它与第(i)部分中的结果相比如何?
(iii)现在, 去掉所有wage≥20的观测, 于是, 样本中剩下每个人每小时工资都不足20美元。做第(i) 部分中的回归, 并评论educ的系数。(由于正常的断尾回归模型都假定y是连续的, 所以理论上我们去掉wage≥20还是去掉wage>20都无所谓。但在这个应用研究中, 由于有些人正好每个小时挣20美元, 所以二者略有差异。)
(iv)利用第(ii) 部分中的样本, 应用断尾回归[上断点为log(20) ] .假定第(i) 部分中得到的估计值是一致的,这个断尾回归能够重新得到整个总体中的教育回报估计值吗?
人口特征方面的数据。目的是想考察快餐店是否在黑人更集中的区域收取更高的价格。
(i)求出样本中prpblck和income的平均值及其标准差。prpblck和income的度量单位是什么?
(ii)考虑一个模型,用人口中黑人比例和收入中位数来解释苏打饮料的价格psoda:
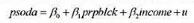
用OLS估计这个模型并以方程的形式报告结果, 包括样本容量和R。(报告估计值时不要使用科学计数法。)解释prpblck的系数。你认为它在经济上算大吗?
(iii) 将第(ii)部分得到的估计值与psoda对prpblck进行简单回归得到的估计值进行比较。控制收入变量后,这种歧视效应是更大还是更小了?
(iv)收入价格弹性为常数的模型可能更加适合。报告如下模型的估计值:

(vi)求出1og(income)和prppov的相关系数。大致符合你的预期吗?
(vii)评价如下说法:“由于log(income)和prppov如此高度相关,所以它们不该进入同一个回归。”
考虑简单回归模型
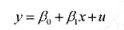
令z为x的二值工具变量。运用式(15.10),ⅣV估计量,可以写成: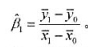 其中,
其中,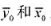 是zi=0的那部分样本中yi和xi的样本平均值,而
是zi=0的那部分样本中yi和xi的样本平均值,而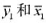 是zi=1的那部分样本中yi和xi的样本平均值。该估计量称为群组估计量, 它是由沃尔德(Wald, 1940) 最先提出。
是zi=1的那部分样本中yi和xi的样本平均值。该估计量称为群组估计量, 它是由沃尔德(Wald, 1940) 最先提出。
A.2000 $100 $9 $200000
B.2250 $200 $4 $450000
C.3000 $80 $2 $240000
D.3100 $150 $1 $465000

其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型,并报告通常的标准误。为使得ai的期望值可以非零,你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差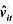 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用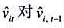 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?
(vi)定义支出的总(或长期)效应为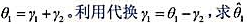 的标准误。
的标准误。
A.与被排除在外的前定变量个数正好相等
B.小于被排除在外的前定变量个数
C.大于被排除在外的前定变量个数
D.以上三种情况都有可能发生
















