

 如果结果不匹配,请
如果结果不匹配,请 
 更多“在数据安全领域常用的P2DR模型中,P、D和R代表的是()。”相关的问题
更多“在数据安全领域常用的P2DR模型中,P、D和R代表的是()。”相关的问题
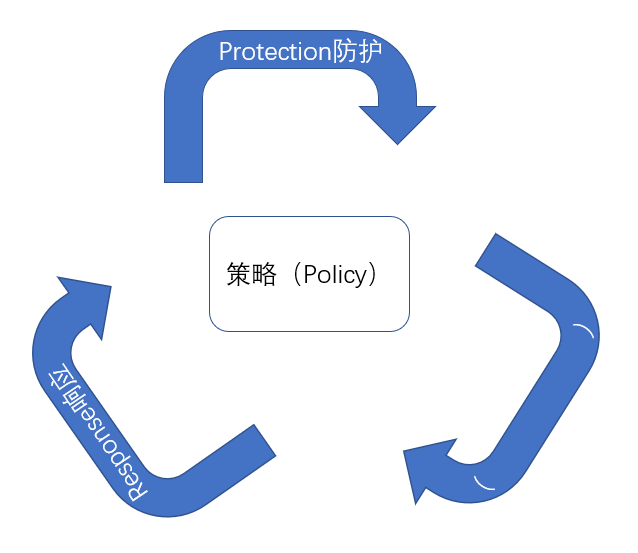
A.执行(do)
B.检测(detection)
C.数据(data)
D.持续(direction)
利用PHILLIPS.RAW中的数据回答本题。
(i)利用整个数据集,用OLS估计静态菲利普斯曲线方程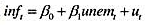 并以常用形式报告结果。
并以常用形式报告结果。
(ii)从第(i)部分中求OLS残差ut并通过ut对ut-1的回归中求出p。(在这个回归中包含一个截距项没问题。)有序列相关的强烈证据吗?
(iii)现在通过迭代普莱斯-温斯顿程序估计静态菲利普斯曲线模型。将β1的估计值与表12.2中得到的估计值相比较。添加以后的年份,估计值有很大变化吗?
(iv)不用普莱斯-温斯顿检验,而是使用迭代科克伦-奥卡特检验。p的最终估计值有多相似?β1的PW和CO估计值有多相似?
数据集401KSUBS.RAW包含了净金融财富(nenfa)、被调查者年龄(age)、家庭年收入(inc)、家庭规模(fsize)方面的信息,以及参与美国个人的特定养老金计划方面的信息。财富和收入变量都以千美元为单位记录。对于这里的问题,只使用无子女已婚者数据(marr=1,fsize=2)。
(i)数据集中有多少无子女已婚夫妇?
(ii)利用OLS估计模型
nettfa=β0+β1inc+β2age+u;
并以常用格式报告结果。解释斜率系数。斜率估计值有何惊人之处吗?
(iii)第(ii)部分的回归截距有重要意义吗?请解释。
(iv)在1%的显著性水平上,针对H0:β2>1检验H0: β2=1,求出p值。你能拒绝H0吗?
(V)如果你做一个nettfa对inc的简单回归,inc的斜率估计值与第(ii)部分的估计值有很大不同吗?为什么?
A.关键词提取是指用人工方法提取文章关键词的方法
B.TF-IDF模型是关键词提取的经典方法
C.文本中出现次数最多的词最能代表文本的主题
D.这个问题设计数据挖掘,文本处理,信息检索等领域
(i) 估计一个将respond与resplast和avggift联系起来的线性概率模型。以通常的形式报告结果, 并解释变量resplast的系数。
(ii)过去捐助的平均水平看来会影响做出捐助响应的概率吗?
(iii) 在模型中增加变量propres p并解释其系数。(这里须注意, propresp增加1是最大可能变化。)
(iv) 在回归中增加propres p以后, resp last的系数有何变化?这讲得过去吗?
(v) 在模型中增加每年寄出邮件的数量mail year。它的估计影响有多大?为什么它不是邮件数量对响应的因果关系的一个较好的估计?
















