 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
在一个有截距项的回归模型估计结果中,已知总的离差平方和SST=49,归直线所能解释的离差平方和SSE=35,那么可知残差平方和SSR等于()。
A.10
B.12
C.18
D.14
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.10
B.12
C.18
D.14
如果结果不匹配,请 联系老师 获取答案
 更多“在一个有截距项的回归模型估计结果中,已知总的离差平方和SST…”相关的问题
更多“在一个有截距项的回归模型估计结果中,已知总的离差平方和SST…”相关的问题

其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型,并报告通常的标准误。为使得ai的期望值可以非零,你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差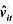 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用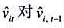 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?
(vi)定义支出的总(或长期)效应为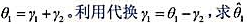 的标准误。
的标准误。
利用PHILLIPS.RAW中的数据回答本题。
(i)利用整个数据集,用OLS估计静态菲利普斯曲线方程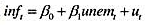 并以常用形式报告结果。
并以常用形式报告结果。
(ii)从第(i)部分中求OLS残差ut并通过ut对ut-1的回归中求出p。(在这个回归中包含一个截距项没问题。)有序列相关的强烈证据吗?
(iii)现在通过迭代普莱斯-温斯顿程序估计静态菲利普斯曲线模型。将β1的估计值与表12.2中得到的估计值相比较。添加以后的年份,估计值有很大变化吗?
(iv)不用普莱斯-温斯顿检验,而是使用迭代科克伦-奥卡特检验。p的最终估计值有多相似?β1的PW和CO估计值有多相似?
(i)考虑静态非观测效应模型

其中,enrolit表示学区总注册学生人数,lunchit表示学区中学生有资格享受学校午餐计划的百分数。(因此lunchit是学区贫穷率的一个相当好的度量指标。)证明:若平均每个学生的真实支出提高10%,则math4it约改变β1/10个百分点。
(ii)利用一阶差分估计第(i)部分中的模型。最简单的方法就是在一阶差分方程中包含一个截距项和1994~1998年度虚拟变量。解释支出变量的系数。
(iii)现在,在模型中添加支出变量的一阶滞后,并用一阶差分重新估计。注意你又失去了一年的数据,所以你只能用始于1994年的变化。讨论即期和滞后支出变量的系数和显著性。
(iv)求第(iii)部分中一阶差分回归的异方差-稳健标准误。支出变量的这些标准误与第(iii)部分相比如何?
(v)现在,求对异方差性和序列相关都保持稳健的标准误。这对滞后支出变量的显著性有何影响?
(vi)通过进行一个AR(1)序列相关检验,验证差分误差rit=Δuit含有负序列相关。
(vii)基于充分稳健的联合检验,模型中有必要包含学生注册人数和午餐项目变量吗?
A.如果使用横断面数据进行回归分析会使r2的值上升。
B.回归分析对估计利息收入不再适用。
C.一些没有包括在模型中的新的因素引起了收入的变化。
D.线性回归分析会提高模型的可信度。
数据集401KSUBS.RAW包含了净金融财富(nenfa)、被调查者年龄(age)、家庭年收入(inc)、家庭规模(fsize)方面的信息,以及参与美国个人的特定养老金计划方面的信息。财富和收入变量都以千美元为单位记录。对于这里的问题,只使用无子女已婚者数据(marr=1,fsize=2)。
(i)数据集中有多少无子女已婚夫妇?
(ii)利用OLS估计模型
nettfa=β0+β1inc+β2age+u;
并以常用格式报告结果。解释斜率系数。斜率估计值有何惊人之处吗?
(iii)第(ii)部分的回归截距有重要意义吗?请解释。
(iv)在1%的显著性水平上,针对H0:β2>1检验H0: β2=1,求出p值。你能拒绝H0吗?
(V)如果你做一个nettfa对inc的简单回归,inc的斜率估计值与第(ii)部分的估计值有很大不同吗?为什么?
A.$4050
B.$4030
C.$3970
D.$3830
(i)利用WAGEPRC.RAW中的数据,估计第11章习题5中的分布滞后模型。用回归教材(12.14)来检验AR(1)序列相关。
(ii)用迭代的科克伦-奥卡特方法重新估计这个模型。长期倾向的新估计值是多少?
(iii)用迭代C0求出LRP的标准误。(这要求你估计一个修正方程。)判断LRP估计值在5%的水平上是否统计显著异于1?
本题使用HTV.RAW中的数据。
(i)基于整个样木, 利用解释变量educ、abil、exper、nc、west、south和urban, 利用OLS估计log(wage)的一个模型。报告教育的估计回报及其标准误。
(ii)现在, 仅利用educ<16的人群来估计第(i) 部分中的方程。样本损失了多大的比例?现在, 多读一年书的估计回报是多少?它与第(i)部分中的结果相比如何?
(iii)现在, 去掉所有wage≥20的观测, 于是, 样本中剩下每个人每小时工资都不足20美元。做第(i) 部分中的回归, 并评论educ的系数。(由于正常的断尾回归模型都假定y是连续的, 所以理论上我们去掉wage≥20还是去掉wage>20都无所谓。但在这个应用研究中, 由于有些人正好每个小时挣20美元, 所以二者略有差异。)
(iv)利用第(ii) 部分中的样本, 应用断尾回归[上断点为log(20) ] .假定第(i) 部分中得到的估计值是一致的,这个断尾回归能够重新得到整个总体中的教育回报估计值吗?
人口特征方面的数据。目的是想考察快餐店是否在黑人更集中的区域收取更高的价格。
(i)求出样本中prpblck和income的平均值及其标准差。prpblck和income的度量单位是什么?
(ii)考虑一个模型,用人口中黑人比例和收入中位数来解释苏打饮料的价格psoda:
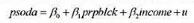
用OLS估计这个模型并以方程的形式报告结果, 包括样本容量和R。(报告估计值时不要使用科学计数法。)解释prpblck的系数。你认为它在经济上算大吗?
(iii) 将第(ii)部分得到的估计值与psoda对prpblck进行简单回归得到的估计值进行比较。控制收入变量后,这种歧视效应是更大还是更小了?
(iv)收入价格弹性为常数的模型可能更加适合。报告如下模型的估计值:

(vi)求出1og(income)和prppov的相关系数。大致符合你的预期吗?
(vii)评价如下说法:“由于log(income)和prppov如此高度相关,所以它们不该进入同一个回归。”

















