

 如果结果不匹配,请
如果结果不匹配,请 
 更多“Spark任务的Executor可以执行多个task()”相关的问题
更多“Spark任务的Executor可以执行多个task()”相关的问题
第1题
编写程序,计算某个单词在一组文件中出现的频率。对每个文件,可以生成一个返回该文件统计结果的,
编写程序,计算某个单词在一组文件中出现的频率。对每个文件,可以生成一个返回该文件统计结果的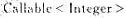 ,然后将它们提交Executor。当所有任务完成时,得到一组Future,对它们合并可得到结果。
,然后将它们提交Executor。当所有任务完成时,得到一组Future,对它们合并可得到结果。
第2题
下列关于Worker、Executor、Task说法正确的是()。
A.每个Executor可以运行多个Task
B.每个Worker可以运行多个Executor
C.每个Worker只能为一个拓扑运行Executor
D.每个Executor可以运行不同组件的Task
第3题
关于HIVE,以下说法不正确的是()。
A.HIVE构建于HDFS和MapReduce之上
B.HIVE使用类SQL的HQL语言作为查询接口
C.HIVE的并行执行主要依赖MapReduce来实现
D.HIVE不能运行在Spark上
第9题
spark-submit配置项中()表示每个executor使用的内核数。
A.--num-executorsNUM
B.--executor-memoryMEM
C.--total-executor-coresNUM
D.--executor-couresNUM
















